Consider a Single-Layer Neural Network with 1 neuron, 1 input for simplicity. The neuron has the following:
Input:
Weight:
Bias:
Function:
Activation: ReLU(z) = max(0, z)
Output: y
The typical Feed-forward process works as follows:
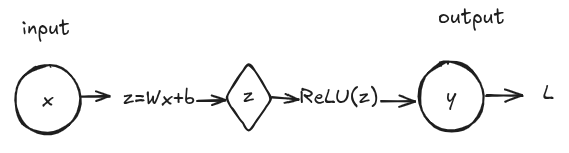
Once we get the output we have to compare it with the actual label/value . This is achieved by using a loss function as follows: . Where is the label we want to predict. Once the loss value is found we backpropagate gradients to update the weights, so the loss can be decreased. We take gradients as follows: , a gradient is just a derivative. As depends on , we use the chain rule to take partial derivatives and multiply them:
. When we calculate derivative of activation, we check if , the neuron activates and we pass the gradient, if the neuron dies and the gradient doesn't pass, hence why we add bias to reduce the risk of neuron dying.
After gradients have been calculated we update the weights by moving opposite to the gradients as: , where is the learning rate which is usually a really small number to prevent gradients from taking large steps. The bias is updated the same way: . This step for updating trainable parameters (weights and biases) using computed gradients is called Gradient Descent.
This process of Feed-forward and Backpropagation continues till the loss converges to a minimum. One iteration of going through inputs and going back through gradients is called a Full Pass. The main goal is to minimize loss as much as possible.The lower the loss the more accurate the model.
This was just a simple single layer, single neuron neural network there's way more complex ones with more neurons and more layers to capture nuanced data, but the good thing: the structure is mostly the same with more neurons stacked. And so understanding more complex nn architectures becomes a little easier.
How does a Neural Network work?
2026-01-13